Cuidado al diseñar el
esquema
Antes de hacer consultas, lo primero que deberías hacer es
diseñar el esquema y quizá es uno de los pasos más importantes si la
aplicación. La memoria necesaria para una tabla es el número de entradas por el
tamaño de una fila ( de perogrullo ) por
lo que las tablas deben tener un tamaño aceptable. Es lógico que un campo
nombre sea varchar pero, ¿qué pasa con un código postal que solo va a tener 5
caracteres… siempre?
Veamos lo que pasa internamente:
Valor CHAR (5) Almacenamiento requerido VARCHAR (5) Almacenamiento requerido
'' ' ' 5 bytes '' 1 byte
‘ab’ 'ab ' 5
bytes 'ab' 3
bytes
'abcde' 'abcde' 5 bytes 'abcde' 6 bytes
Como ves, a tamaño completo, no tiene mucho sentido guardar
un varchar de 5 caracteres teniendo en cuenta que, si siempre va a ocupar lo
máximo, ocupará más que si fuera un char.
Es bastante común tener tablas de las que solo seleccionemos
algunas columnas en concreto con asiduidad. Imagina por ejemplo la tabla de un
usuario en la que podemos llegar a guardar un montón de información como su
fecha de nacimiento, departamento al que pertenece, etc. Pero habitualmente
accederás a su nombre de usuario, correo, contraseña y poco más. Para esos
casos, es buena idea particionar la tabla:
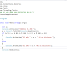
CREATE TABLE usuarios {
id INT unsigned not null auto_increment,
usuario VARCHAR(20) not null,
password VARCHAR(40) not null,
email VARCHAR(40),
PRIMARY KEY(id)
}
CREATE
TABLE datos_usuario {
id_usuario INT unsigned not null,
id_departamento INT unsigned,
fecha_nacimiento
DATE,
dni CHAR(9),
PRIMARY KEY
(id_usuario)
}
Los datos que usamos frecuentemente los mantenemos en una
tabla mientras que los que usamos con menos frecuencia los dejamos en otra,
esto hará que la tabla menos frecuente ocupe menos memoria.
Nada de SELECT *
A menudo, especialmente durante
el desarrollo, nos vemos tentados a escribir SELECT * para cualquier consulta
en la que nos traigamos datos de una tabla. Esto es un error en la mayoría de
las ocasiones ya que estarás trayendo datos que, probablemente, no necesites.
Lo que es aun peor es que la tabla puede crecer en número de columnas en el
futuro, lo cual implica que traerás aun más datos que no necesitarás.
Limita las consultas a las columnas que necesites.
Encadena SELECT o usa JOIN pero no ambos
Aparte de que son menos mantenibles y legibles, tienen un
alto impacto en cuanto a recursos usados. Por regla general además, es
recomendable no usar SELECTs anidados y usar únicamente JOINs ya que el
rendimiento es casi siempre mejor. Recuerda que, por regla general, puedes
convertir un SELECT anidado en un JOIN fácilmente:
SELECT
usuario
FROM
usuarios
WHERE id IN
(
SELECT id
FROM datos_usuario
WHERE departamento = 1
)
Ahora con JOINs
SELECT usuarios.usuario
FROM usuarios
INNER JOIN datos_usuario ON usuarios.id = datos_usuario.id
WHERE datos_usuario.departamento = 1;
Este es un error bastante común para los iniciados al SQL ya
que la primera consulta es más “natural” para el programador.
Evita los filtros de texto
Una de las cosas que más impactan sobre el rendimiento de la
base de datos es el hacer búsquedas de texto en cadenas, especialmente en
campos de tipo TEXT y usando %.